
Métricas ágiles Velocidad, Cycle Time, Throughput y CFD: El problema no son los números, es cómo los usamos
Muchas organizaciones miden velocidad, cycle time y throughput… pero pocas entienden qué están midiendo realmente. Aquí explico cuándo cada métrica genera valor, cuándo no usarla y cómo evitar que destruya la agilidad.
En muchas organizaciones se habla de métricas ágiles.
Se reportan números en comités. Se muestran gráficos en dashboards. Se comparan resultados entre equipos.
Y, sin embargo, la predictibilidad no mejora. La presión aumenta. La conversación se vuelve defensiva.
Mi experiencia acompañando equipos en banca, retail y tecnología me ha mostrado algo claro:
Las métricas ágiles no fracasan por falta de datos, fracasan cuando se usan sin entender el sistema que están midiendo.
Velocidad, Cycle Time, Throughput y CFD no son herramientas de control. Son instrumentos de comprensión.
La diferencia está en cómo se usan.
¿Qué entendemos realmente por métricas ágiles?
Cuando hablamos de métricas ágiles, no hablamos de indicadores para evaluar personas.
Hablamos de señales del sistema.
Indicadores que permiten observar:
- Capacidad real de entrega
- Fluidez del trabajo
- Acumulación y bloqueos
- Variabilidad
- Predictibilidad
Una métrica bien utilizada genera conversación sobre el sistema.
Una métrica mal utilizada genera presión sobre el equipo.
VELOCIDAD: Capacidad, no productividad
La Velocidad mide la cantidad de puntos de historia completados por Sprint.
En Scrum, suele utilizarse como referencia para planificar próximos compromisos.
Para qué sí sirve
Estimar capacidad futura del equipo
Ajustar expectativas con el Product Owner
Detectar cambios en estabilidad del Sprint
Proteger al equipo de sobrecompromiso
Cuándo no usarla
Para comparar equipos
Para evaluar desempeño individual
Para exigir mejora constante
En entornos que no trabajan con estimación relativa
Errores comunes
Convertirla en KPI organizativo
Ignorar variabilidad entre Sprints
Cambiar criterios de estimación sin recalibrar
Confundir más puntos con más valor
Un ejemplo real
En una transformación en retail, un equipo tenía una velocidad estable alrededor de 40 puntos por Sprint.
En una reunión de planificación trimestral, una manager preguntó:
“Si ya están en 40, ¿por qué no planificamos 55?”
Quizas, el razonamiento te suene lógico. Más puntos, más avance.
Sin embargo, al analizar el contexto, el equipo tenía:
Dependencias externas frecuentes
Interrupciones de negocio
QA compartido con otros equipos
Entonces forzar el compromiso no habría mejorado la entrega. Habría aumentado la inestabilidad.
Entonces utilizamos la velocidad histórica para mostrar capacidad real y variabilidad.
La conversación cambió.
Ya no se habló de “subir velocidad”, sino de reducir interrupciones.
La métrica dejó de ser presión. Se convirtió en argumento sistémico.
THROUGHPUT: Volumen real de entrega
El Throughput mide cuántos ítems se completan en un período determinado.
No depende de puntos. Se basa en trabajo finalizado.
Para qué sí sirve
Forecast probabilístico
Planificación basada en datos históricos
Equipos que no usan estimación relativa
Simulaciones tipo Monte Carlo
Cuándo no usarlo
Cuando los ítems no tienen tamaño relativamente homogéneo
Sin una definición clara de “Done”
Si se mezclan tipos de trabajo sin clasificación
Errores comunes
No considerar variabilidad
Comparar equipos con contextos distintos
Convertirlo en ranking
Ignorar dispersión estadística
Un ejemplo real
En una consultoría tecnológica que pertencí hace unos años, el Product Owner que era parte de la misma firma, necesitaba responder al comité:
“¿Cuándo terminaremos este backlog?”
En lugar de reestimar todo, analizamos Throughput histórico.
El equipo completaba entre 15 y 20 ítems por semana.
Con simulación probabilística, mostramos que había un 85% de probabilidad de finalizar entre 6 y 8 semanas.
El comité pidió fijar 6 semanas como compromiso.
La conversación giró hacia probabilidades reales, no promesas lineales, es decir hubo coordinación, acuerdos, compromisos en levantar impedimentos que provienen del cliente, menos pausas
Y asú el Throughput permitió hablar en términos de mitigar riesgos y previsibilidad real.
CUMULATIVE FLOW DIAGRAM (CFD): La radiografía del sistema
El CFD muestra cómo se distribuye el trabajo en el tiempo entre los distintos estados del flujo.
Permite observar acumulaciones invisibles en el día a día.
Para qué sí sirve*
Detectar cuellos estructurales (bottle necks)
Visualizar exceso de WIP (Work in progress)
Analizar estabilidad del sistema
Facilitar conversaciones con management
Cuándo no usarlo
Si el flujo no está claramente definido
En equipos con muy bajo volumen de trabajo
Como simple gráfico de reporte sin análisis
Errores comunes
No interpretar expansión de bandas
No conectar el gráfico con decisiones concretas
Usarlo como evidencia de “trabajan mucho”
Un ejemplo real
En un equipo donde trabajé con Kanban y que su flujo si lo tenía bien definido, el cliente percibía baja entrega, es decir lenta.
El equipo insistía en que trabajaba al máximo.
El CFD mostró algo distinto:
La banda de “In Progress” crecía de forma constante. La banda de “Done” crecía lentamente.
No era falta de esfuerzo. Era exceso de muchas tareas abiertas a la vez, y esto pasó a pesar que ya existía un WIP.
Entonces para ser reales con al entrega del equipo, tuve que ajustar el WIP, y eso si cambió el comportamiento del sistema.
De este modo el CFD transformó todo, y así el cliente cambió la percepción de la baja entrega.
CYCLE TIME: eficiencia del flujo, no rapidez individual
El Cycle Time mide cuánto tarda un ítem desde que comienza a trabajarse hasta que se termina.
Es una métrica clave en entornos de flujo continuo.
Para qué sí sirve
Detectar cuellos de botella
Medir predictibilidad real
Evaluar estabilidad del sistema
Reducir tiempo de entrega al cliente
Cuándo no usarlo
Sin definición clara de estados
Sin límites de WIP
Para presionar entregas individuales
En trabajos de tamaño extremadamente variable sin segmentación
Errores comunes
Analizar solo el promedio
No diferenciar tipos de trabajo
Ignorar bloqueos externos
No revisar dependencias inter-área
Un ejemplo real
En un cliente del sector banca donde trabajé como consultor, el manager de todo el proyecto que involucraba 8 squads, se quejó con todos a través de teams por los retrasos continuos.
El equipo trabajaba en flujo continuo.
Al analizar el Cycle Time, observamos que había pasado de 6 a 14 días en tres meses.
El problema no estaba en la ejecución técnica.
El CFD mostraba acumulación en una fase de validación legal.
Había demasiados ítems en progreso y ningún límite claro de WIP.
Reducimos trabajo simultáneo. Acordamos capacidad de validación con el área legal. Repriorizamos flujo.
Dos meses después, el Cycle Time volvió a niveles estables.
No se aceleró al equipo. Se estabilizó el sistema.
Cuadro comparativo: cuándo priorizar cada métrica
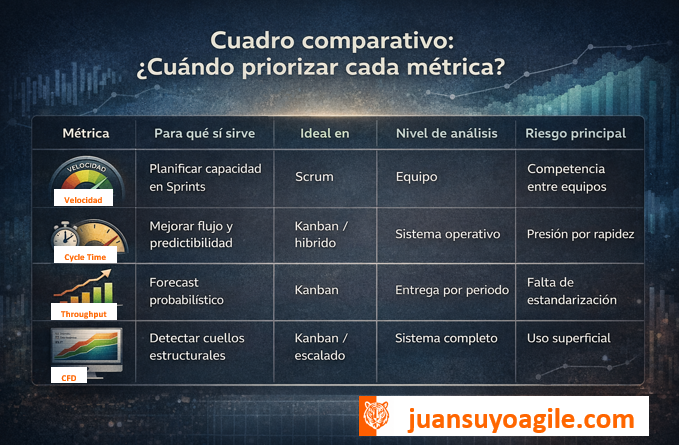
Métricas ágiles y entorno organizativo
Las métricas no transforman organizaciones por sí solas.
Lo que transforma es la conversación que generan.
Si las métricas se usan para controlar personas, la agilidad se deteriora.
Si se usan para entender el sistema, la mejora se vuelve sostenible.
He visto organizaciones obsesionadas con dashboards que no cambian decisiones.
Y he visto equipos que, con una sola métrica bien interpretada, modifican su forma de trabajar en semanas.
La diferencia no está en el gráfico. Está en el uso.
Mi conclusión
Las métricas ágiles no miden talento.
Miden estabilidad del sistema.
No sirven para demostrar que un equipo es “bueno” o “malo”.
Sirven para mostrar dónde el sistema necesita ajustarse.
Cuando se entienden así, dejan de ser números.
Se convierten en herramientas de transformación real.
Deja un comentario